THE CORPUS OF TURKISH YOUTH LANGUAGE (CoTY)
For my PhD dissertation, I compiled and constructed a specialized corpus, the Corpus of Turkish Youth Language (CoTY), in order to explore the previously unattained research area of contemporary urban language spoken by Turkish youth. The corpus was compiled with the aims of:
► describing the architecture of Turkish youth language in terms of its macro and micro structures,
► exploring the socio-pragmatic dynamics and patterns in this dyadic and multi-party interaction,
► identifying and discussing the discursive strategies employed with regard to co-construction of specific interactional events,
► highlighting potential linguistic and discursive trends in contemporary Turkish.
The CoTY is designed to encompass various modes and mediums of youth interaction and expand over the years, yet my dissertation study specifically focuses on spoken data.
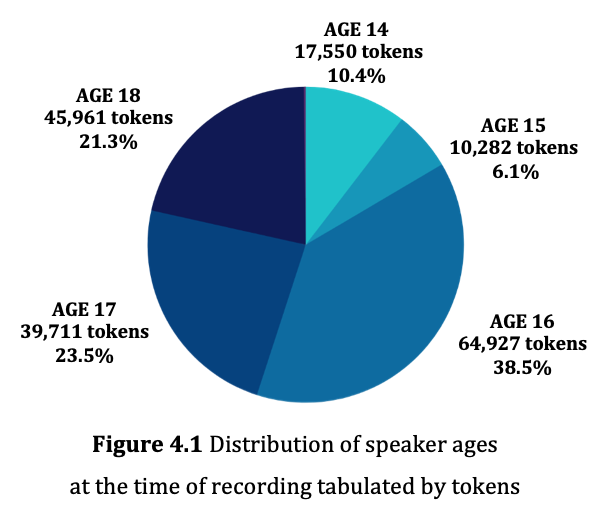
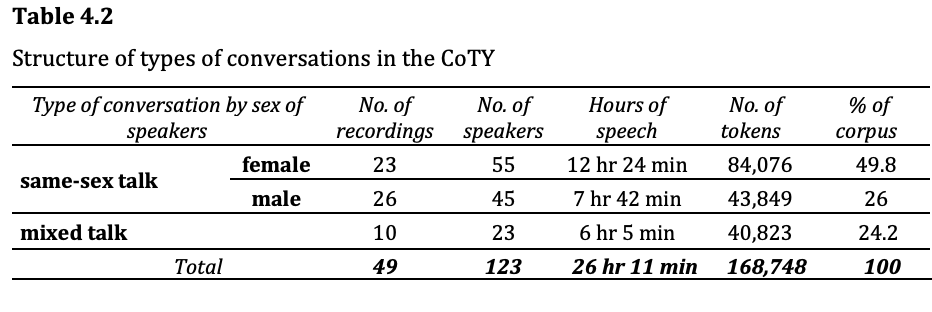
The current version of The Corpus of Turkish Youth Language (CoTY) comprise 168,748 tokens of 24,736 word types within the single domain of informal conversation exclusively among friends. The corpus has 123 unique speakers (62 females and 61 males) and consists of 49 conversations which correspond to 26 hours 11 minutes of interaction. The language spoken is Turkish along with occasional code-switches to English, as well as some words or expressions from French, Russian and Japanese. Though the number of speakers are balanced with regard to sex, female speech make of 58% of the corpus, while 42% of the data is male speech. In terms of the distribution of data across speaker groups; 49.8% of the corpus is exclusively female-female speech, 26% is exclusively male-male speech, and 24.2% has female and male speakers.
Within the scope of my dissertation, I explored the CoTY in terms of its structural composition, topical and lexical characteristics, and the interactional markers with a focus on (i) response tokens, (ii) vocatives, (iii) vague expressions, and (iv) intensifiers. I examined the types, patterns and salient pragmatic functions of these markers in the corpus. Through this study, my goal was to establish a solid baseline data for the future scholarly inquiries regarding the multiple facets of linguistic practices of the young speakers such as co-construction, negotiation, and creativity observed within spoken discourse.
The major motive behind constructing the first spoken corpus of Turkish youth language has three interrelated tenets. Firstly, the corpus aims to contribute to the growing body of studies in corpus studies and corpus methodology in Turkey. Secondly, the it aims to provide a cross-linguistic perspective for the existing literature on youth language research which so far have focused on English and Spanish, and to some extent German and Nordic languages. An additional overarching purpose of the corpus is to promote open science practices in linguistics by illustrating the affordances of corpus tools in terms of sustaining reproducibility, consistency, and transparency of language research. The conscious decisions made by the researcher regarding the utilization of contributory public participation model (Shirk, et al., 2012) to integrate public engagement; the use of an open source corpus construction and annotation software EXMARaLDA to ensure the sustainable development of the corpus in terms of size and levels of annotation in the future; providing access to the schemes for conventions, annotation, and metadata adapted or developed for the corpus in an open access repository also resonate with the aims of open science movement.
TO CITE THE CORPUS: Efeoglu-Ozcan, E. (2022). The corpus of Turkish Youth Language (CoTY): The compilation and interactional dynamics of a spoken corpus [Unpublished doctoral dissertation]. Middle East Technical University.